- Métodos (funcións pre-definidas)
- Datos estruturados: listas e dicionarios
- Bucles for
Neste apartado imos facer un xogo para dúas ou máis persoas: unha codifica unha mensaxe en galego cun algoritmo de transposición e a outra ten que decodificalo utilizando a técnica da análise de frecuencias de letras. O que imos facer vale para textos dunha certa lonxitude escritos nunha lingua natural, pero non para codificar/decodificar un número segredo, como por exemplo un contrasinal ou un PIN. Para iso haberá outras técnicas.
Antes de inventar máquinas para codificar/decodificar mensaxes (diríamos antes do século XIX, máis ou menos) a criptografía clásica ten utilizado distintas técnicas de codificado de mensaxes utilizando un algoritmo de trasposición alfabética. Collemos a mesma letra en todo o texto e a substituímos por outra (ou por un carácter) aleatoria, que só vai coñecer a persoa que ten que decodificar. Un dos algoritmos deste tipo máis famosos foi o de Xulio César. Se queres ler máis ao respecto podes facelo na nosa seción de Algoritmos famosos.
1. Codificar unha mensaxe por trasposición
Comecemos codificando unha mensaxe cun código ben coñecido e famoso, o código Morse. O código Morse era un código público (moi funcional, por certo) e calquera podía codificar e decodificar unha mensaxe.
- Para iso creamos un dicionario de Python, chamado morse onde almacenamos por pares os caracteres das linguas galegas, castelán e inglesa (serán as claves) e os seus equivalentes en Morse (serán os valores):
morse = {"a":".-","b":"-...","c":"-.-.","d":"-..","e":".","f":"..-.","g":"--.","h":"....","i":"..","j":".---",
"k":"-.-","l":".-..","m":"--","n":"-.","ñ":"--.--","o":"---","p":".--.","q":"--.-","r":".-.","s":"...","t":"_","u":"..-",
"v":"...-","w":".--","x":"-..-","y":"-.--","z":"--..","0":"-----","1":".----","2":"..---","3":"...--","4":"....-",
"5":".....","6":"-....","7":"--...","8":"---..","9":"----.","!":"-.-.--","?":"..--..",".":".-.-.-"," ":" ","'":"--..--"}
- Pedimos o texto a codificar:
texto = str(input('Introduce texto a morsear> ')) #utilizamos str() para que todo sexa unha cadea de caracteres.
- Tan só poñemos as minúsculas no dicionario, por que imos poñer o noso texto en minúsculas para abreviar. Para iso usamos o método lower(), que convirte as letras en minúsculas. de igual xeito, existe upper() para facelo en maiúsculas.
texto.lower() #converte o texto en todo minúsculas
- Creamos unha lista baleira, novo_texto e imos engadindo as letras codificadas. Percorremos a cadea (en minúsculas, con lower) letra por letra co bucle for, e para cada unha delas engadimos á nova cadea o seu par asociado, morse[letra], no dicionario:
novo_texto = ''
for letra in texto.lower():
novo_texto = novo_texto + morse[letra]
Exercicios:
- Proba a codificar a famosa mensaxe SOS (saves our souls), que aínda a día de hoxe é unha das mensaxes codificadas máis famosas do mundo.
2. Crea un código propio, substituíndo no diccionario anterior as letras de morse polo teu propio código. No próximo apartado trataremos de descifrar os códigos dos demais.
2. Compactar unha mensaxe.
Antes de meternos coa decodificación de mensaxes imos aprender a compacar unha mensaxe, para que ocupe menos, eliminando os espazos en branco, comas, puntos e outros caracteres.
- Collamos o texto a codificar e gardémolo nunha cadea. Lembra que ten que ter cando menos 100 caracteres para que despois poidamos decodificalo. Neste exemplo poñemos un máis curto por brevidade:
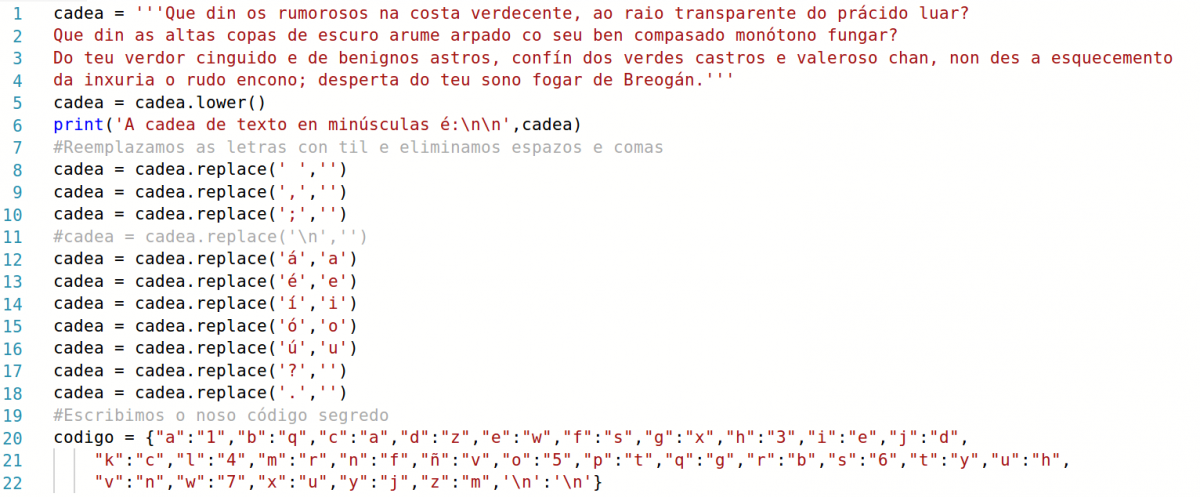
cadea = '''Que din os rumorosos na costa verdecente, ao raio transparente do prácido luar? Que din as altas copas de escuro arume arpado co seu ben compasado monótono fungar?
Do teu verdor cinguido e de benignos astros, confín dos verdes castros e valeroso chan, non des a esquecemento da inxuria o rudo encono; desperta do teu sono fogar de Breogán.'''
- Para comprobar a lonxitude utilizamos len():
print('O texto ten ',len(cadea), ' caracteres')
- Agora queremos converter todos os caracteres en maiúsculas ou en minúsculas:
cadea = cadea.upper() #se quixeramos conservar o texto orixinal, podemos crear unha cadea nova para gardar o texto modificado.
- E tamén eliminar comas, puntos, e outros caracteres. Ademáis tamén queremos converter as vogais con til en vogais sen til. Imos facelo co método replace():
cadea = cadea.replace(' ','') #eliminados o espazos
cadea = cadea.replace(',','')
cadea = cadea.replace(';','')
cadea = cadea.replace('\n','') #eliminamos o saltos de liña, neste exemplo non imos empregalo.
cadea = cadea.replace('Á','A') #substituimos as letras con til; lembras que as temos en maiúsculas neste caso
cadea = cadea.replace('É','E')
cadea = cadea.replace('Í','I')
cadea = cadea.replace('Ó','O')
cadea = cadea.replace('Ú','U')
cadea = cadea.replace('?','')
cadea = cadea.replace('.','') #os caracteres que elimines non tes que incluilos no dicionario do código
print(cadea) #comprobamos que todo vai ben
Aplicamos todo o anterior ao noso texto para ver como queda:
Exercicios:
- Modifica o programa anterior no que creabas un código e engade os pasos para compactar primeiro a túa mensaxe.
- Crea unha función que faga isto de eliminar/substituír, dado como parámetro o caracter a eliminar. Poden ser dúas funcións, unha para eliminar e outra para substituír.
- Crea unha lista con todos os posibles parámetros da función, e substitúe o código do exercicio 1, por un programa que mediante un bucle vaia aplicando a función eliminar aos diversos parámetros. (Lembra definir a variable cadea como global.)
3. Decodificar por análise de frecuencias
No noso caso, inventamos un código, e por non complicar decidimos NON codificar os saltos de liña. Como o fixemos?. Incluindo no dicionario do código o par '\n':'\n'
As catro primeiras estrofas de Os Pinos quedan así codificadas, con saltos de liñá ao final da estrofa :
ghwzef56bhr5b5656f1a56y1nwbzwawfyw15b1e5yb1f6t1bwfywz5tb1aez54h1b
ghwzef1614y16a5t16zww6ahb51bhrw1bt1z5a56whqwfa5rt161z5r5f5y5f5shfx1b
z5ywhnwbz5baefxhez5wzwqwfexf5616yb56a5fsefz56nwbzw6a16yb56wn14wb565a31ff5fzw61w6ghwawrwfy5
z1efuhbe15bhz5wfa5f5zw6twby1z5ywh65f5s5x1bzwqbw5x1f
Supoñamos que temos o texto codificado como o anterior e, por suposto, non temos acceso ao código empregado. Parece imposible de decodificar agás que atrapemos a un enemigo que teña o código. Isto é o que lle pasaba aos espías e servizos de intelixenxia ata o século XIX. Pero a ciencia da lingüística veu na súa axuda, afirmando e demostrando que en calquera lingua natural a frecuencia das letras nun texto de certa lonxitude vai ser similar. Por exemplo en galego ou castelán as letras máis frecuentes van ser un E, unha A ou un O (en castelán a frecuencia de letras é E A O S R N I D L C T U M P B G V Y Q H F Z J Ñ X K W). Isto que axuda no noso traballo?. Pois temos que substituir os caracteres máis frecuentes por letras con máis frecuencia e lograremos decodificar a nosa mensaxe en pouco tempo (isto é relativo, claro ;-)
É decir, o noso traballo agora é, dado un texto nunha cadea, facer unha análise de frecuencias dos caracteres. Vexamos como.
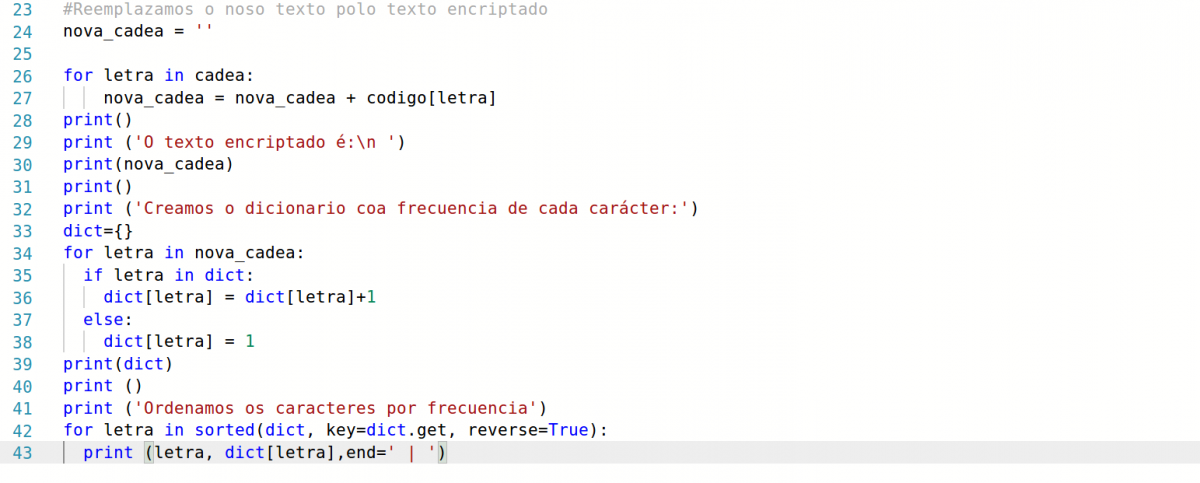
- Creamos un dicionario baleiro onde imos ir gardando os caracteres como clave e as súas frecuencias como valor:
dict = {}
- Agora, dun xeito parecido ao que fixemos para codificar, percorremos a cadea. Cando teñamos un caracter novo, o gardamos con valor 1. Cando xa esté no dicionario aumentamos a súa frecuencia en 1:
for letra in cadea: #usamos a variable letra pero podería ser caracter ou calquera outra
if letra in dict:
dict[letra] = dict[letra]+1 #cando xa a temos gardada
else:
dict[letra] = 1 #se aínda non a temos gardada, a garda e pon o valor a 1
- Para ver o que fixemos imprimimos o dicionario:
print(dict).
Como vemos, temos o valor de repetición de cada caracter.
- Se por comodidade de lectura queremos ordenalo por valor, de maior a menor, facemos:
for letra in sorted(dict, key=dict.get, reverse=True):
print (letra, dict[letra],end=' | ')
Estamos a usar o método sorted(), con dous argumentos: key= dict.get, que colle as claves e as ordena segundo o seu valor, e reverse= True, que as ordena de maior a menor valor. Ademais engadimos o comando end=' | ' para separar a impresión.
No noso texto codificado de exemplo o resultado é:
5 40 | w 33 | 1 28 | f 24 | b 23 | 6 23 | z 20 | h 14 | a 13 | y 12 | e 10 | t 6 | r 5 | x 5 | n 4 | 4 3 | q 3 | s 3 |
3 | g 3 | 3 1 | u 1 |
- Para decodificar iríamos substituíndo os caracteres con máis frecuencia no texto codificado polos caracteres máis frecuentes en galego. Para iso podemos utilizar o método replace() ou ben a función que se solicitou como exercicio anteriormente.
Aínda así teremos que ter un pouco de paciencia, pois non irán na mesma orde. Por exemplo, no noso caso, que era un texto curto, a frecuencia do texto non codificado era :
O 40 | E 33 | A 28 | N 24 | R 23 | S 23 | D 20 | U 14 | C 13 | T 12 | I 10 | P 6 | M 5 | G 5 | V 4 | L 3 | B 3 | Q 3 | F 3 | X 1 | H 1 | . 1 |
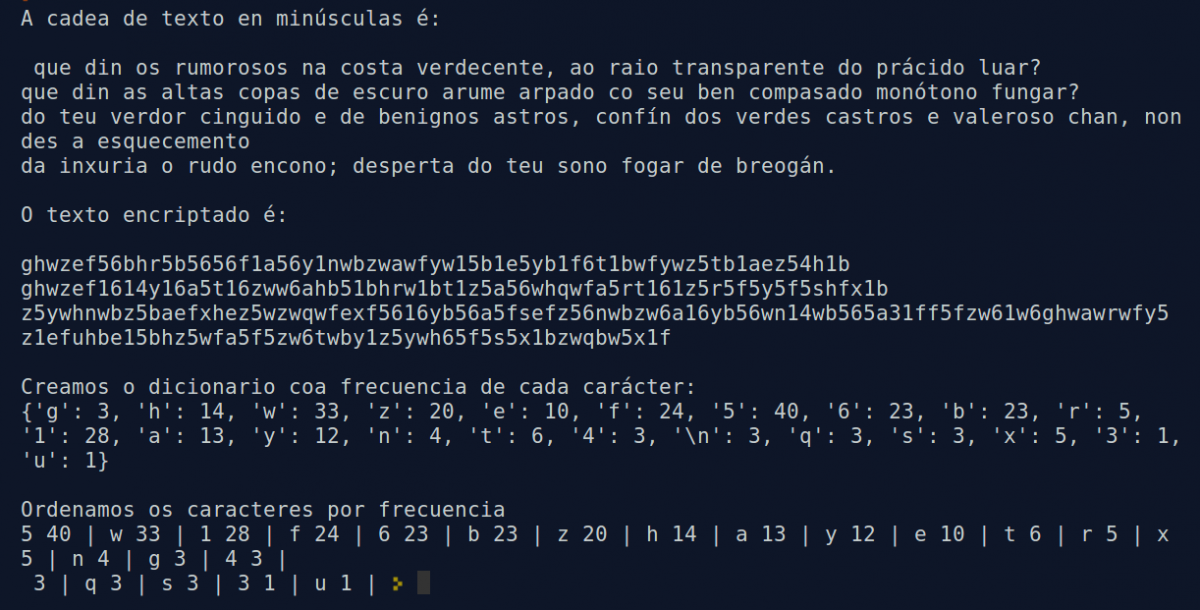
É decir, o caracter máis frecuente no noso texto é o O, que é o 3º caracter máis frecuente, en vez de o E.
Pero é, que en contra do que aparece nos filmes e novelas, o traballo de investigador/espía pode ser MOI aburrido ;-)
Exercicio:
- Botas en falta Repl.it?. Nesta ocasión pareceunos mellor que sexas ti o que probe o código, porque algunhas veces temos que picar código desde cero.
- Colle un texto en galego de máis de 100 caracteres e codifícao con un código inventado por ti. Dallo a un compañeiro e que o decodifique. A súa vez, que el faga o mesmo contigo. Antes de entregarllo asegúrate que a frecuencia das letras no texto é similar á da lingua normal, senón terá moito chollo ;-)
Listas agrupadas: contar palabras O xogo de codificar/decodificar